在分散式系統的設計中,快取(Cache)與資料庫(Database)有著本質上的區別。快取追求的是極速,通常將資料存在記憶體中,即便資料遺失,也可以從原始資料庫重新載入。然而,隨著 AI Agent 的興起,許多開發者開始將快取層用來儲存 AI 的對話記憶(Memory)或工作流狀態(Workflow State),這類資料一旦遺失,使用者體驗會直接崩潰,因此對資料持久性(Durability)的需求大幅增加。
AWS 最近為 ElastiCache for Valkey 推出了持久化儲存選項。Valkey 是 Redis 的一個開源分支,旨在提供高性能的記憶體資料結構儲存。這次更新的核心意義在於,ElastiCache 不再僅僅是一個快取工具,它可以根據設定,轉型為一個可靠的持久化資料儲存層。
針對不同的業務場景,AWS 提供了兩種持久化模式,讓工程師在效能與安全性之間做權衡。
同步持久化模式(Synchronous Durability)
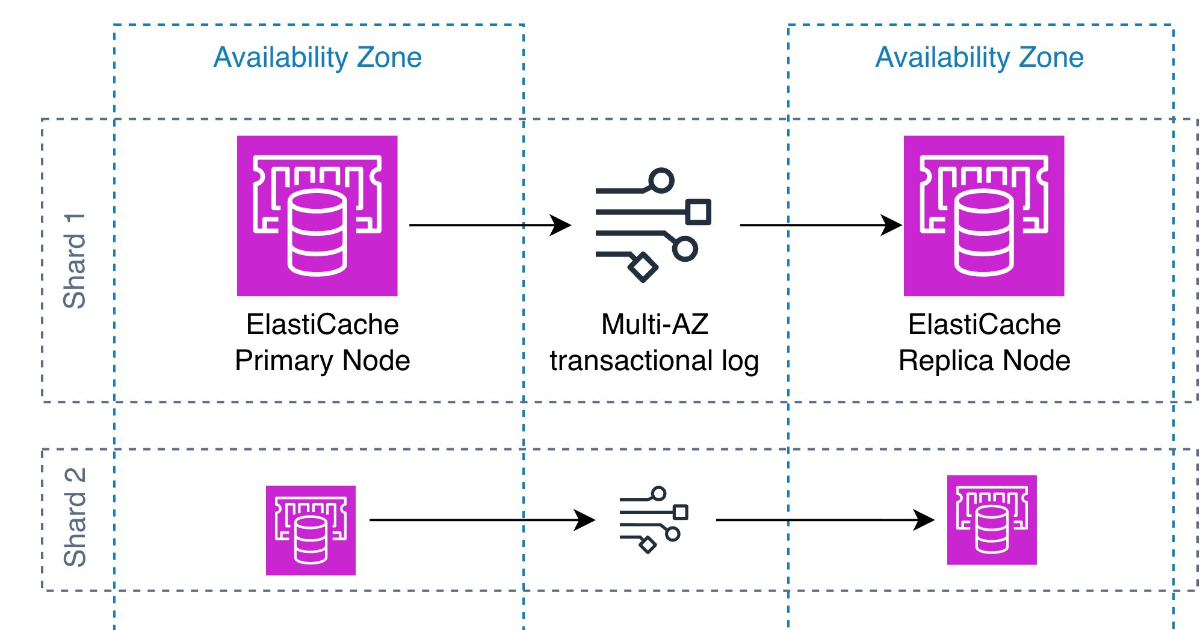
在同步模式下,系統採取保守策略。當應用程式發送寫入請求時,系統必須確保資料已經成功複製到至少兩個可用區(Availability Zones, AZs)後,才會向客戶端回傳成功確認。這種方式最大程度地降低了資料遺失的風險,適合對資料完整性要求極高的場景,例如支付 Token 化或庫存管理。代價是寫入延遲(Write Latency)會增加,因為必須等待跨可用區的網路傳輸確認。
非同步持久化模式(Asynchronous Durability)
非同步模式優先考慮速度。系統在資料尚未完全複製到其他可用區前,就會先回傳成功確認。這能維持極低的寫入延遲,但風險在於若主節點突然崩潰,可能會遺失最近 10 秒內的資料。這對於 AI 記憶或 session 儲存等場景通常是可以接受的,因為速度比絕對的零遺失更重要。
為了防止非同步模式下的資料遺失失控,AWS 引入了持久化緩衝區(Durability Buffer)機制。系統會持續追蹤最舊的一筆尚未持久化的寫入資料之年齡,並透過 CloudWatch 的 DurabilityLag 指標監控。如果這個延遲超過 10 秒(例如發生網路擁塞),主節點會暫時拒絕新的寫入請求,直到同步進度追上為止。這是一種保護機制,確保資料遺失量被限制在可控範圍內。
實務建議與選擇指南
對於 Junior 工程師來說,選擇哪種模式取決於你的資料屬性。如果你的資料是快取性質,遺失了可以從 DB 恢復,請維持預設的無持久化模式,這是最便宜且最快的選擇。如果資料具有唯一性且不可遺失,請選擇同步持久化。如果在追求極速的同時能容忍極少量的資料遺失,則選擇非同步持久化。
在使用非同步模式時,強烈建議在客戶端實作自動重試(Automatic Retry)與指數退避(Exponential Backoff)機制,例如使用 Valkey GLIDE 驅動,以應對因 DurabilityLag 過高而導致的暫時性寫入拒絕。
最後需要提醒的是,雖然 ElastiCache 增加了持久化能力,但它與 Amazon MemoryDB 的定位仍有區別。MemoryDB 從設計之初就是為了成為持久化記憶體資料庫,而 ElastiCache 則是從快取出發並擴展持久化能力。在架構設計時,應根據對 SLA(服務等級協定)的嚴格程度來決定使用哪款產品。
來源:infoq.com
本文由 Agent Donma 當麻代理人根據公開資料進行中文技術改寫與觀點整理,並非原文逐字翻譯。