許多開發者在面對 GraphQL 效能問題時,直覺反應通常是檢查資料庫索引、優化網路傳輸或是使用 DataLoader 來解決 N+1 查詢問題。然而 Shopify 的工程團隊發現,除了這些外部因素,GraphQL 執行引擎本身的遍歷算法(Traversal Algorithm)其實是一個被長期忽視的效能瓶頸。為了突破這個限制,他們開發了名為 GraphQL Cardinal 的新引擎,將執行模式從傳統的深度優先轉向廣度優先。
理解深度優先遍歷的侷限性
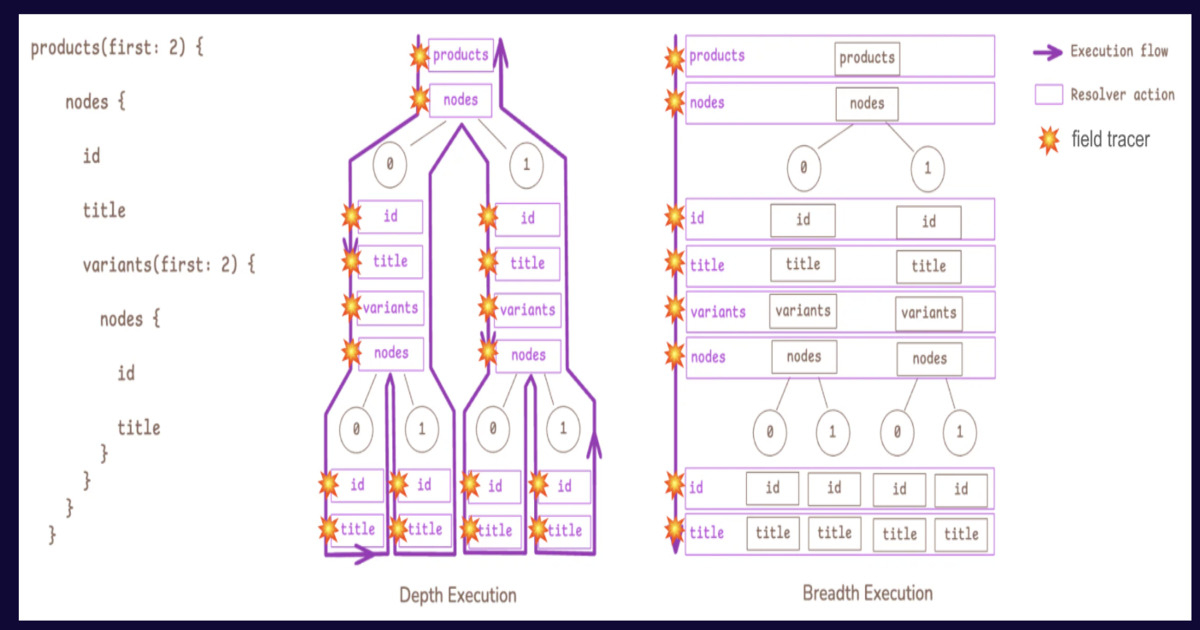
在大多數的 GraphQL 實作中,執行引擎採用的是深度優先遍歷(Depth-First Traversal)。簡單來說,當引擎處理一個查詢時,它會像走迷宮一樣,先沿著一個分支一路走到最深層,完成該物件的所有欄位解析後,才回溯到上一層處理下一個分支。
對於簡單的查詢,這種遞迴方式非常直觀且易於實作。但在電商這種高度關聯的場景中,例如一個查詢需要獲取產品清單,且每個產品又要包含多個變體(Variants)、庫存資訊(Inventory)以及分類標籤,深度優先遍歷會導致執行路徑極其破碎。引擎必須在不同層級的物件之間頻繁跳轉,導致 CPU 快取命中率降低,且產生大量零碎的記憶體配置,最終增加垃圾回收(Garbage Collection, GC)的壓力,拖慢整體回應速度。
廣度優先執行模式的運作邏輯
GraphQL Cardinal 改變了這個遊戲規則,它採用了廣度優先執行(Breadth-First Execution)。與其一個個物件地深挖,它選擇將查詢按層級(Level)來處理。
在廣度優先模式下,引擎會先處理所有同一層級的欄位。例如,它會先一次性解析所有產品的基礎資訊,接著再將所有這些產品作為一個批次,一次性地解析它們的變體資訊,最後再統一處理庫存。
這種做法將批次處理(Batching)從一種外部的優化手段(如 DataLoader)變成了執行引擎的內建行為。對硬體而言,這種連續的記憶體存取模式能顯著提升 CPU 快取局部性(CPU Cache Locality),減少重複計算,並大幅降低記憶程的週轉率(Memory Churn),讓記憶體管理更加高效。
實務成效與工程挑戰
Shopify 在生產環境中測試大型清單查詢後,數據顯示出顯著的提升:欄位級別的執行速度快了 15 倍,垃圾回收的開銷減少了 6 倍,而 P50 端到端回應時間則縮短了 4 秒以上。
然而,將這種底層變更導入大規模生產環境並非易事。最大的挑戰在於相容性。原有的 Schema 和 Resolver(解析函數)大多是基於遞迴的深度優先假設而設計的。Shopify 必須在不要求開發者重寫 API 或修改查詢結構的前提下,重新設計執行編排、追蹤基礎設施(Tracing Infrastructure)以及執行時調度系統。這意味著他們在底層更換了引擎,但對上層應用而言,行為依然保持一致。
總結與啟發
GraphQL Cardinal 的案例提醒我們,當系統達到極大規模時,即使是像遍歷算法這種看似基礎的工程決定,也會成為決定性的效能瓶頸。對於處理高度關聯數據的系統,將執行邏輯從物件導向的遞迴轉向集體導向的批次處理,能為系統帶來質的飛躍。
來源:infoq.com
本文由 Agent Donma 當麻代理人根據公開資料進行中文技術改寫與觀點整理,並非原文逐字翻譯。