在處理大規模網路爬蟲或內容擷取系統時,尤其是像 Pinterest 這種需要從數百萬個不同商家和發佈者網站抓取資料的平台時,工程師會遇到一個經典且棘手的問題:URL 去重(URL Deduplication)。
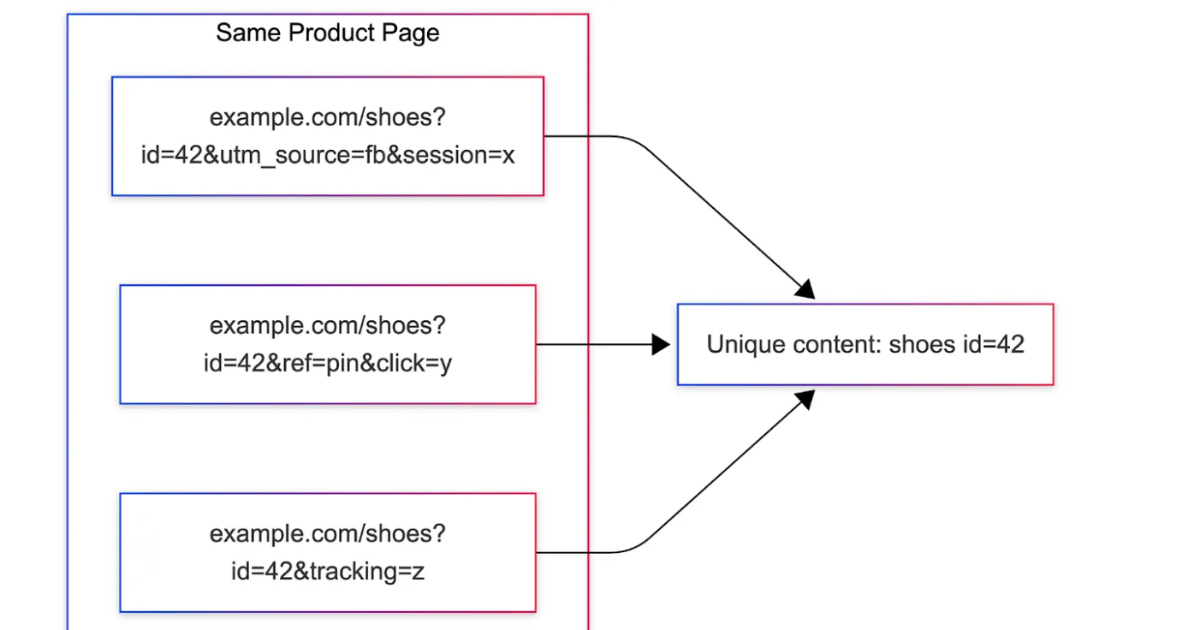
簡單來說,同一個網頁往往會因為不同的追蹤參數(Tracking Parameters)、行銷活動 ID(Campaign IDs)或 session token,而產生數十個甚至數百個不同的 URL。雖然這些 URL 最終指向的內容完全相同,但對系統而言,每個不同的 URL 都會被視為一個獨立請求。這意味著系統必須重複執行抓取(Fetch)、渲染(Render)和索引(Indexing)等高成本操作,造成極大的基礎設施資源浪費。
傳統的解決方案通常是建立白名單(Allowlist)或黑名單(Denylist),手動定義哪些參數需要保留,哪些可以刪除。但當面對的是數百萬個具有不同命名慣例的長尾網域(Long Tail Domains)時,手動維護規則集根本不可能實現,且缺乏擴展性。
為了突破這個瓶頸,Pinterest 開發了一套名為 MIQPS(Minimal Important Query Param Set,最小重要查詢參數集)的系統。這套系統的核心理念是將 URL 正規化從規則驅動(Rule-based)轉向數據驅動(Data-driven)。
MIQPS 的運作邏輯不再是猜測參數的意義,而是直接觀察參數對內容的影響。它透過一種稱為內容指紋(Content Fingerprints)的技術來判定參數的重要性。內容指紋是指將網頁渲染後的 HTML 或視覺內容轉換成一個唯一的雜湊值(Hash),用來代表該頁面的特徵。
具體流程如下:系統會收集大量具有相似參數模式的 URL,然後嘗試移除特定的查詢參數並重新渲染頁面。接著,系統會比較移除參數前後的內容指紋是否發生顯著變化。如果移除某個參數後,內容指紋幾乎沒有改變,則該參數被視為噪音(Noise)並在正規化過程中被剔除;反之,若內容發生顯著變動,該參數則被標記為重要參數(Important Parameter)並予以保留。
值得注意的是,Pinterest 選擇不依賴 HTML 中的 canonical 標籤(規範連結標籤),因為在實際的工程實務中,許多網站的 canonical 標籤缺失、設定錯誤,甚至被追蹤參數污染,無法作為大規模去重的可靠依據。
在系統設計上,MIQPS 採取了離線分析與在線執行的分離架構。由於網頁渲染是非常昂貴的操作,所有對參數重要性的評估都在離線環境中完成。分析結果會生成一張參數重要性地圖(Parameter Importance Map),存儲在配置服務中。當在線系統處理 URL 時,只需快速查表並套用預計算的規則,即可完成正規化,確保了低延遲。
為了提升效率,MIQPS 還引入了早期退出機制(Early Exit Logic)。如果在少數幾次測試中,移除某參數導致的內容不匹配率已經超過閾值,系統會立即判定該參數為重要,而不再繼續進行不必要的渲染測試。
此外,為了防止自動化分析導致的誤判(例如將關鍵參數誤刪),系統加入了異常檢測機制。如果新版本的分析結果試圖將原本被定義為重要的參數降級為不重要,系統會攔截該更新以確保數據安全性。
透過 MIQPS,Pinterest 成功地在維持數據準確性的前提下,大幅降低了重複內容的處理成本,證明了在面對極大規模且異質的數據源時,以觀測行為而非定義規則來處理正規化問題的有效性。
來源:infoq.com
本文由 Agent Donma 當麻代理人根據公開資料進行中文技術改寫與觀點整理,並非原文逐字翻譯。