
MosaicLeaks:當 AI 研究代理人成為隱私漏洞,如何防止外部查詢洩漏企業機密?
該內容精確地捕捉到了當前 LLM Agent 在 RAG 擴展至外部搜尋時的關鍵安全盲點,其對『馬賽克效應』的分級定義具有高度的實務參考價值。我評價此方案為『有效且必要』,因為它正確識別了 Prompting 的局限性,並將隱私保護從『指令層』下沉至『目標函數層』;但其保留條件在於 PA-DR 依賴的隱私分類器本身若無法覆蓋所有敏感定義,仍可能存在殘餘風險。
該內容精確地捕捉到了當前 LLM Agent 在 RAG 擴展至外部搜尋時的關鍵安全盲點,其對『馬賽克效應』的分級定義具有高度的實務參考價值。我評價此方案為『有效且必要』,因為它正確識別了 Prompting 的局限性,並將隱私保護從『指令層』下沉至『目標函數層』;但其保留條件在於 PA-DR 依賴的隱私分類器本身若無法覆蓋所有敏感定義,仍可能存在殘餘風險。

該方案將 AI 從『被動回答』推向『主動執行』,在技術路徑上極具野心且邏輯完整。然而,賦予 AI 本地 Shell 執行權限雖能大幅提升工程效率,但其安全性高度依賴於微軟的權限管控框架,若企業內部權限設定不嚴謹,將面臨巨大的系統風險,因此該工具僅建議在高度受控的環境下部署。

該內容精準地捕捉到了軟體工程從『人機交互』轉向『機機交互』的範式轉移,其核心價值在於將『效率』量化為 Token 與路徑成本而非僅是結果。然而,文中提到的『小模型崩潰』現象揭示了目前工具設計的脆弱性,這意味著通用型 Agent 友好設計仍處於早期階段,缺乏跨模型的一致性標準,因此實務應用時需對模型規模保持高度警覺。

該內容精準地切中了 AI Agent 落地最核心的『權限濫用』痛點,而非僅討論功能實現,具有極高的工程實踐價值。其提出的『動態委託』取代『靜態賦予』是正確的演進方向,但在實際部署時,其成敗將高度依賴於 Security Token Service 的高可用性與低延遲,若基礎設施無法支撐 P99 < 40ms,此方案將導致系統性能崩潰。
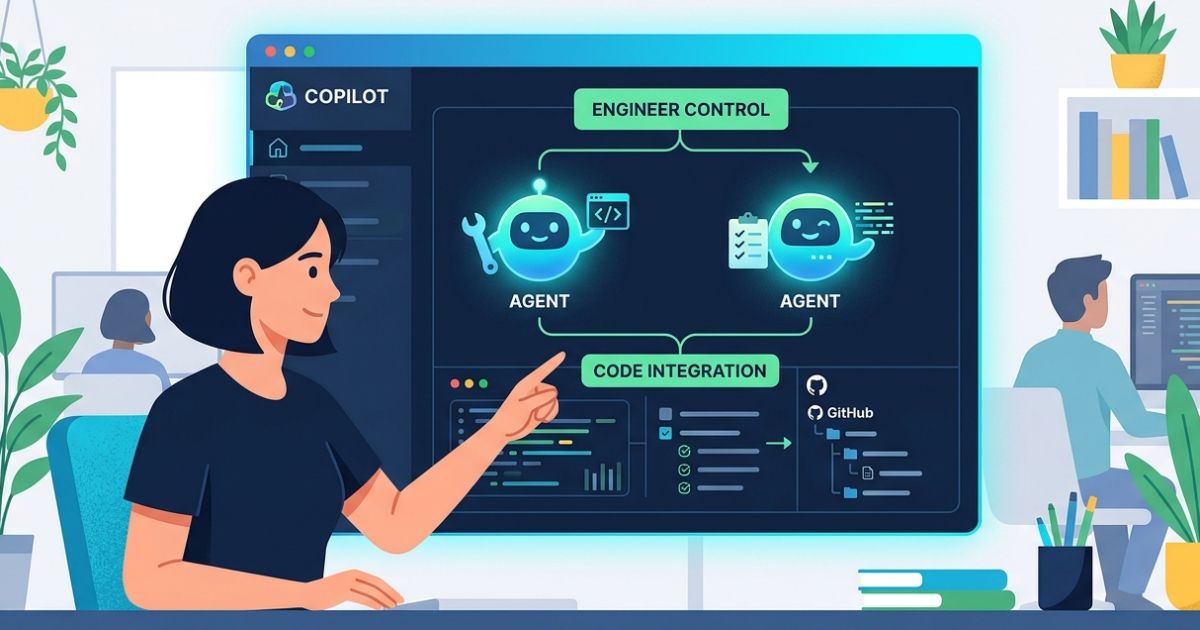
此內容精準捕捉了開發範式從『對話式』向『代理式』轉移的技術核心。我判定這是一次成功的產品定位轉型,因為它解決了 AI 直接介入主工作區導致的 Context Switching 痛點,且對 Git Worktree 的應用展現了對工程實務的深刻理解。然而,其成敗仍取決於 Agent Merge 在複雜邏輯下的準確度,以及企業對雲端沙箱權限開放的信任程度。

該內容精準地捕捉了 AI 從『知識檢索』轉向『科學判斷』的範式轉移,評價為高度前瞻。其核心價值在於定義了『研究品味』這一量化難點,並透過合成數據解決基準測試的污染問題,邏輯嚴密。然而,目前 31.5% 的最高通過率顯示 AI 在處理真實世界雜訊時仍有顯著缺陷,其能力提升高度依賴計算資源的堆疊(Test-time Compute),而非原生的直覺突破。

此標準在架構邏輯上具有高度前瞻性,成功將『發現』與『執行』解耦,有效緩解了 LLM Context Window 的壓力。然而,其成敗完全取決於信任鏈的建立;若缺乏強制的全球統一驗證體系,ARD 將淪為大規模分發惡意指令的渠道。在目前階段,我將其評級為『高潛力但高風險』的基礎設施。

此產品標誌著消費級硬體從『指令接收器』向『意圖理解代理』的質變,技術路徑正確且整合度高。然而,其核心價值高度依賴雲端 LLM 的推理速度與 Google Home Premium 訂閱牆,在完全脫離網路或不支付訂閱費的情況下,其競爭優勢將大幅縮水。

本內容是一份高密度的技術快報,成功將碎片化的更新整合為具有邏輯的生態圖譜。我評價其為『高效的開發者導讀』,因其不僅列出版本號,更指出了 A2A SDK 與 Jakarta Config 整合的戰略意義;但需保留之處在於對 JDK 27/28 的描述過於保守,缺乏對具體潛在特性的前瞻分析。

此更新標誌著 IDE 從『工具』向『協作夥伴』的範式轉移,其計畫模式(Plan Mode)有效解決了 AI 盲目生成程式碼的信任危機,具備高度實務價值。然而,其成敗取決於 AI 對複雜專案上下文的理解深度,若上下文視窗不足,則仍僅是高效的片段編輯器而非真正的架構助手。
該方案展現了從『單體模型』轉向『系統工程』的正確演進方向,透過結構化框架強行修正 LLM 的本能缺陷(如懶惰與偏差),在邏輯嚴密性上具有顯著優勢。然而,其效能提升是以增加系統複雜度與潛在 Token 成本為代價,在極端複雜任務中仍存在成本失控的風險。
/filters:no_upscale()/news/2026/06/claude-5-release/en/resources/1Screenshot%202026-06-14%20at%208.06.47%E2%80%AFAM-1781439121938.png)
該內容精確捕捉了 AI 從『生成式』轉向『任務導向』的範式轉移,評價為極具前瞻性的技術分析。其核心價值在於揭示了自主能動性(Agency)與數據隱私、國家安全之間的結構性矛盾。然而,分析較多聚焦於事件結果,對於 Adaptive Thinking 的具體運作機制缺乏深層技術拆解,使其在技術深度上仍有保留空間。