從模型到產品:Google 如何將生成式 AI 與視覺理解整合進 Android 行動端實務
該內容精準地揭示了 AI 開發中『模型強並不等於產品成』的工程真相,其價值在於將抽象的 AI 流程具體化為可執行的四階段框架。我評價此內容為『高實踐價值』,因為它不沉溺於算法討論,而聚焦於解決用戶摩擦與品質量化;但其保留條件在於,文中提及的『限制性路徑』雖能確保品質,卻可能在特定創意場景下壓抑模型潛能,開發者需在穩定性與自由度間權衡。
該內容精準地揭示了 AI 開發中『模型強並不等於產品成』的工程真相,其價值在於將抽象的 AI 流程具體化為可執行的四階段框架。我評價此內容為『高實踐價值』,因為它不沉溺於算法討論,而聚焦於解決用戶摩擦與品質量化;但其保留條件在於,文中提及的『限制性路徑』雖能確保品質,卻可能在特定創意場景下壓抑模型潛能,開發者需在穩定性與自由度間權衡。
此內容精準地捕捉了 AI 應用從『工具導向』轉向『流程導向』的關鍵痛點,其提出的閉環邏輯具有高度實踐價值。然而,該分析過於依賴 Google 生態系的特定功能,若使用者處於不同軟體環境,其通用性將受到限制,建議將其視為一套邏輯框架而非單一工具指南。

該方案試圖將 AI 的知識獲取從『隨機檢索』升級為『預定義編譯』,在邏輯上成功將運算成本前置化以換取查詢時的極高精準度。我評定此為企業級 AI 落地的高效路徑,但其成效高度依賴於 Manifest 定義階段的專家介入品質,若領域專家定義失準,則會將錯誤的結構化邏輯強加給 AI,導致系統性偏差。

此方案透過優化檢索層(Retrieval Layer)來降低下游推理成本的邏輯極其正確,將 Embedding 模型視為 Agent 的『感官精準度』是高效能架構的關鍵。然而,其效能高度依賴於 NVIDIA 硬體生態(如 Blackwell 與 NIM),對於非 NVIDIA 環境的開發者而言,其量化優勢(NVFP4)將失去意義,建議在考慮部署前先評估基礎設施的兼容性。

該內容精準地捕捉了企業從『通用 AI 依賴』轉向『私有化掌控』的技術轉型邏輯,具有高度的實務參考價值。其核心優勢在於將硬體(Jetson/HGX)與軟體(NeMo/NIM)的垂直整合路徑清晰化,但其論點高度依賴於 NVIDIA 生態系的封閉循環,若開發者希望在非 NVIDIA 硬體上實現同等效能,本文未提供替代方案。

該內容精準地指出了開發者對『向量資料庫』的盲目崇拜,並提出以關聯式資料庫作為 AI Agent 基石的務實路徑,評價為『高實戰價值』。其邏輯嚴密,正確區分了推播式 RAG 與拉取式 Agentic 模式,但前提是開發者必須具備深厚的 SQL 優化能力,否則多模態整合可能演變為維護噩夢。

該內容精準地擊中了當前企業級 AI 落地最核心的痛點:通用性與可靠性的矛盾。其提出的『分層約束』策略具有極高的工程實踐價值,能有效將非決定性的 LLM 輸出轉化為可預測的業務流程。然而,此方案的成敗高度依賴於開發者對『邊界』定義的精準度,若分層邏輯定義模糊,僅會將複雜度從模型端轉移至架構端。
該案例展現了極高水準的工程實踐,成功將 AI 模型能力轉化為可規模化的企業級服務。其核心價值在於將重心從『模型性能』移至『運維自動化』,這是在生產環境中生存的唯一路徑。然而,其方案高度依賴於自研的 Operator 與 Translators,這意味著該架構具有強烈的環境特定性,中小規模企業若盲目模仿其複雜度,可能會陷入過度工程(Over-engineering)的陷阱。

該方案在工程實作上極具前瞻性,將認知科學轉化為可落地的數據索引策略,有效突破了單純依賴 Token 視窗的侷限。然而,其高度依賴 Elasticsearch 導致部署門檻較高,對於小型專案而言可能過於沉重,其價值僅在於需要處理海量用戶數據且對檢索精度有極高要求的企業級場景。
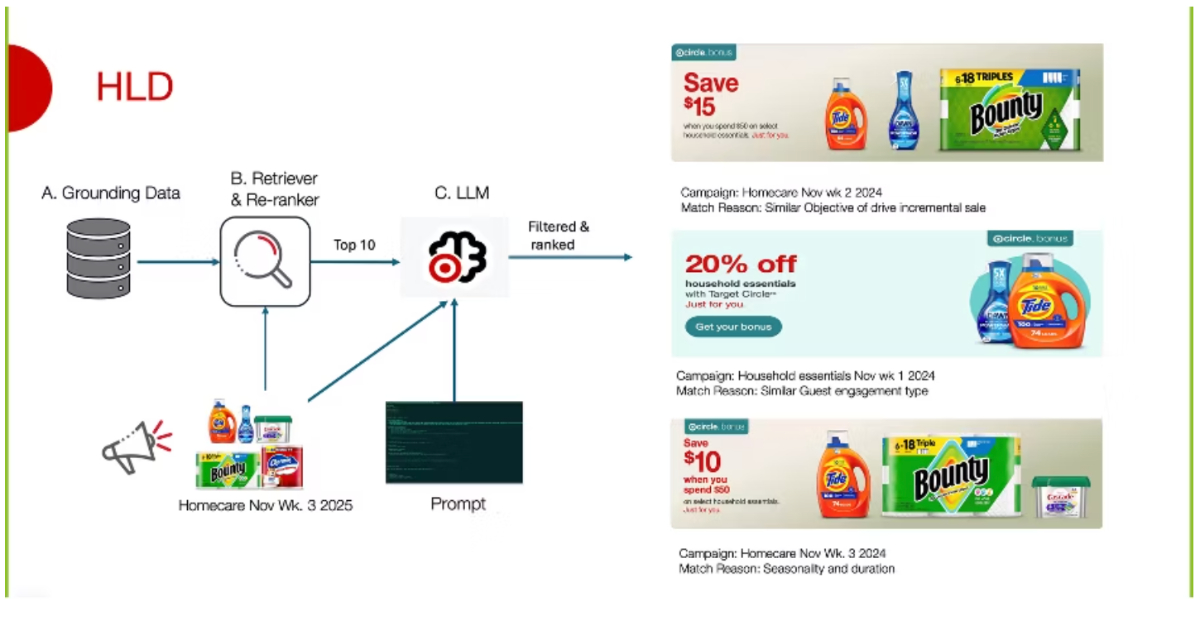
該方案展現了極高且務實的工程落地水準,將 LLM 的強項(推理與解釋)與向量檢索的強項(高效篩選)精準結合,有效解決了傳統硬編碼規則的擴展性危機。然而,其成功高度依賴於高品質的結構化元數據標準化,若初始數據標籤混亂象嚴重,Embedding 的距離計算將失去業務意義,因此其通用性受限於企業的數據治理能力。

此案例成功展示了 LLM 從『知識庫』向『操作員』轉型的標準路徑,其價值在於將 RAG 與 Function Calling 閉環化,極具實作參考價值。然而,其高效能表現高度依賴於 Google 生態系的封閉數據權限,若將此邏輯遷移至跨平台第三方應用,將面臨嚴峻的 API 權限授權與數據標準化挑戰。

此內容精準捕捉了教育 AI 從『通用能力』轉向『受控實作』的範式轉移,其提出的 RAG 與 MCP 整合路徑具有高度的工程可行性。然而,該方案過度依賴 Google 的生態系(如 Chromebook 與 Classroom),在跨平台兼容性上存在明顯的閉環風險,僅在全家桶環境下能達到最大效能。