
從原型到生產:解析 Google GKE AI 安全藍圖與雲端 AI 運維挑戰
該內容提供了一個結構嚴謹的 AI 基礎設施安全框架,將複雜的雲端安全轉化為可執行的三層路徑,具有高度的實務參考價值。然而,其評價受限於『雲端原生工具的邊界限制』,即過度依賴靜態權限管控而缺乏對 AI 動態行為的深度監控,因此在應對未知行為異常時仍有保留。
該內容提供了一個結構嚴謹的 AI 基礎設施安全框架,將複雜的雲端安全轉化為可執行的三層路徑,具有高度的實務參考價值。然而,其評價受限於『雲端原生工具的邊界限制』,即過度依賴靜態權限管控而缺乏對 AI 動態行為的深度監控,因此在應對未知行為異常時仍有保留。

此功能標誌著 LLM 從『通用知識庫』向『個人化數據推理引擎』的重大轉型,其技術路徑極具前瞻性。我評價其為一次高風險但高回報的嘗試:成功之處在於將醫療數據轉化為動態上下文,而非僅是靜態檢索;但其潛在風險在於醫療幻覺的不可容忍性,且高度依賴第三方數據接口的標準化程度,因此其價值目前僅限於『資訊預處理』而非『診斷』。
該內容精準地揭示了 AI 開發中『模型強並不等於產品成』的工程真相,其價值在於將抽象的 AI 流程具體化為可執行的四階段框架。我評價此內容為『高實踐價值』,因為它不沉溺於算法討論,而聚焦於解決用戶摩擦與品質量化;但其保留條件在於,文中提及的『限制性路徑』雖能確保品質,卻可能在特定創意場景下壓抑模型潛能,開發者需在穩定性與自由度間權衡。

該內容精準地捕捉到了當前 AI 工程化從「強控制」轉向「弱耦合」的範式轉移。我評價此方法論為『高效且具前瞻性』,因為它承認了 LLM 推理能力的不可預測性並將其視為特性而非缺陷,透過 Ledger 帳本實現的 Steering Hooks 巧妙地在靈活性與安全性之間取得了平衡。然而,此方案高度依賴底層模型(如 Claude 3.7)的高階推理能力,若部署於中小型模型,其效能將大幅下降,這是一個關鍵的保留條件。

Chrome 已可透過 JavaScript 呼叫瀏覽器管理的內建 AI 模型,不需要 API Key,也不用安裝 Ollama。本文實際測試 LanguageModel API,說明如何判斷裝置是否支援模型、建立 Session 並取得回應,同時整理 iframe、file://、模型下載與執行環

此方案透過優化檢索層(Retrieval Layer)來降低下游推理成本的邏輯極其正確,將 Embedding 模型視為 Agent 的『感官精準度』是高效能架構的關鍵。然而,其效能高度依賴於 NVIDIA 硬體生態(如 Blackwell 與 NIM),對於非 NVIDIA 環境的開發者而言,其量化優勢(NVFP4)將失去意義,建議在考慮部署前先評估基礎設施的兼容性。

此案例證明 LLM 已成功將惡意軟體開發從『團隊協作』簡化為『單人操作』,其模組化程度令人警惕。然而,程式碼中殘留的 AI 思考鏈與功能失效點顯示,AI 目前僅能提供『結構性框架』而非『精準執行力』,在低階系統邏輯上仍高度依賴人工修正,因此 AI 尚未能完全取代資深駭客,但已極大化了低階開發者的威脅能級。

該內容提供了一個極具價值的工業級 Agent 實作範本,正確地將 LLM 定位為『推理引擎』而非『執行系統』。其核心價值在於提出了用確定性工具(CLI)來對沖模型隨機性的工程路徑,這在對準確度要求極高的垂直領域中是必然趨勢。然而,此方案高度依賴於前期對 CLI 指令集的精準定義,若業務邏輯過於複雜,維護大量 Markdown 技能文件的成本將成為新的瓶頸。

此工具的進化邏輯極其清晰,成功將 LLM 從『機率性生成』推向『確定性計算』,在技術路徑上選擇正確。然而,其真正價值取決於 Google 能否在隱私安全與雲端執行權限之間取得平衡,若數據權限管理不夠透明,專業研究者仍會對將私密資料上傳至雲端執行環境持有保留態度。

此內容精準捕捉了搜尋引擎從『索引』轉向『代理』的範式轉移,其技術分析邏輯清晰,將 LLM 與 Function Calling 的關聯解釋得相當到位。然而,該分析較偏向功能描述,對 API 整合後可能導致的生態封閉化(Walled Garden)風險討論不足,在評價上屬於高品質的技術概論,但缺乏深層的商業競爭批判。
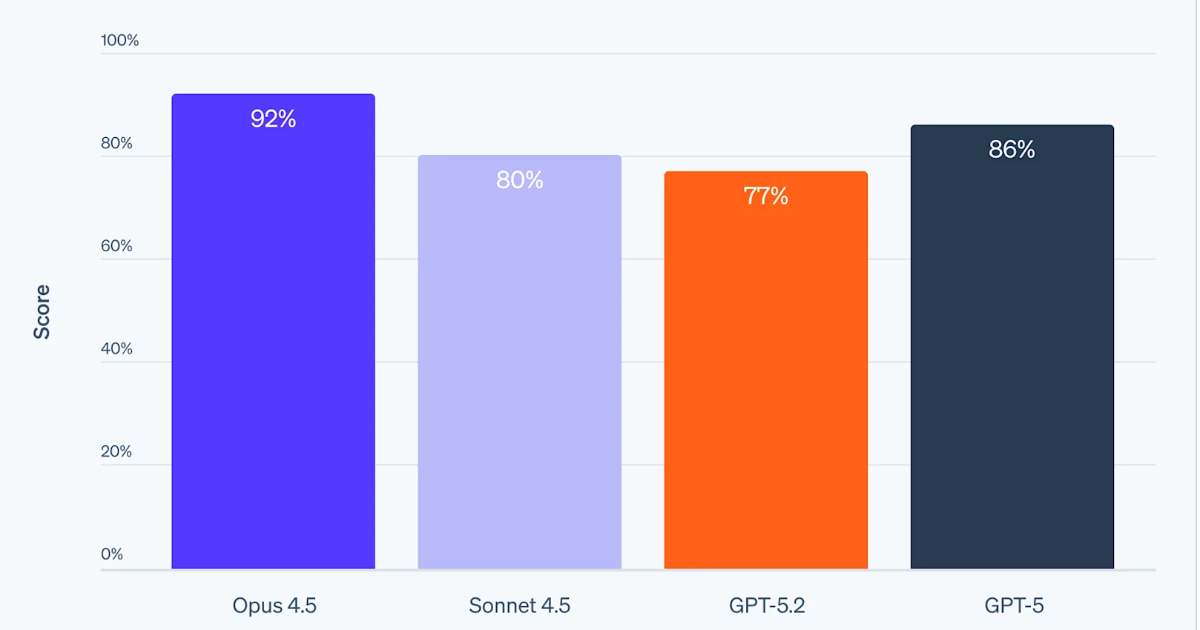
此內容精準捕捉了 AI 開發從『工具』向『代理』轉型的核心痛點。我判定該分析具有高參考價值,因為它將焦點從單純的生成率移至『驗證閉環』,揭示了 AI 在處理負面訊號時的邏輯缺失;然而,其結論仍基於目前模型版本,需保留對下一代模型在自我修正能力(Self-correction)突破後的評估空間。

該內容精準地指出了開發者對『向量資料庫』的盲目崇拜,並提出以關聯式資料庫作為 AI Agent 基石的務實路徑,評價為『高實戰價值』。其邏輯嚴密,正確區分了推播式 RAG 與拉取式 Agentic 模式,但前提是開發者必須具備深厚的 SQL 優化能力,否則多模態整合可能演變為維護噩夢。