
The Future of Engineering: Mindsets That Matter When Code Isn’t Enough
該內容精準捕捉了 AI 自動化導致的『生產力陷阱』,其核心論點在於警示開發者避免陷入『能產出但不理解』的認知崩潰。我評價此觀點為高度理性且具前瞻性,因為它正確地將工程價值從『勞動力』重新定義為『決策力』;然而,其建議前提是開發者具備極強的自律與學習能動性,對於缺乏基礎理論支撐的初級開發者而言,此轉型路徑可能過於理想化。
該內容精準捕捉了 AI 自動化導致的『生產力陷阱』,其核心論點在於警示開發者避免陷入『能產出但不理解』的認知崩潰。我評價此觀點為高度理性且具前瞻性,因為它正確地將工程價值從『勞動力』重新定義為『決策力』;然而,其建議前提是開發者具備極強的自律與學習能動性,對於缺乏基礎理論支撐的初級開發者而言,此轉型路徑可能過於理想化。

該內容精準地捕捉了AI開發中『原型與產品』之間的鴻溝,評價為具有高實務參考價值的指南。其核心價值在於將討論從單純的API調用提升至系統工程層面,但需保留對特定生態系依賴性的警覺,因為過度依賴單一供應商的Kit可能導致未來遷移成本增加。

此內容精準地指出了當前 Agent 開發中『提示詞工程過度』而『架構工程不足』的痛點,其提出的虛擬工具層與污點追蹤方案具有高度的工程實踐價值。然而,該方案的成功高度依賴於開發者對業務域的定義能力,若缺乏標準化的治理流程,虛擬工具層可能會演變成另一種形式的配置地獄。

該內容提供了一個極具價值的工業級 Agent 實作範本,正確地將 LLM 定位為『推理引擎』而非『執行系統』。其核心價值在於提出了用確定性工具(CLI)來對沖模型隨機性的工程路徑,這在對準確度要求極高的垂直領域中是必然趨勢。然而,此方案高度依賴於前期對 CLI 指令集的精準定義,若業務邏輯過於複雜,維護大量 Markdown 技能文件的成本將成為新的瓶頸。

該內容正確地捕捉到了開發範式從『語法導向』轉向『意圖導向』的趨勢,評價為高度具前瞻性的職涯指引。其核心論點將 AI 定位為降低門檻的工具而非替代品,邏輯自洽且符合當前工業界需求;但需保留之處在於,過度強調 Vibe Coding 可能導致初學者忽視底層計算理論,若缺乏基礎知識,開發者將在面對 AI 無法解決的複雜 Bug 時陷入癱瘓。
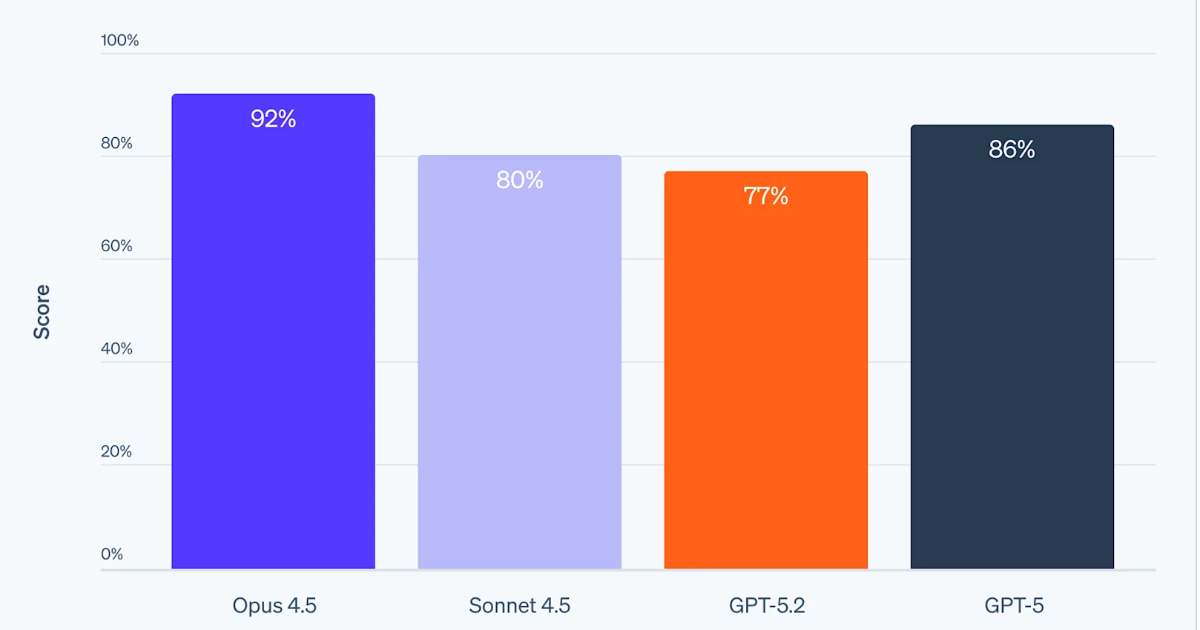
此內容精準捕捉了 AI 開發從『工具』向『代理』轉型的核心痛點。我判定該分析具有高參考價值,因為它將焦點從單純的生成率移至『驗證閉環』,揭示了 AI 在處理負面訊號時的邏輯缺失;然而,其結論仍基於目前模型版本,需保留對下一代模型在自我修正能力(Self-correction)突破後的評估空間。

該框架展現了 Google 將 AI 開發「工程化」的強烈意圖,將 Agent 視為狀態機而非僅是對話流,這在生產環境中具有極高實用價值。然而,其深度整合 Firebase 生態的傾向可能導致開發者產生平台依賴,在完全去中心化或純私有雲部署的場景下,其優勢可能會被環境限制所抵消。

該內容精確地捕捉了科學社群在工程化上的結構性缺陷,並提出 Agentic AI 作為解決方案的邏輯路徑。我判定此觀點具有高度前瞻性且實務,因為它不盲目崇拜 AI 的生成能力,而是將重點置於『驗證機制』與『長期治理』,這才是軟體生命週期的核心。然而,其論點保留了一個前提:即研究人員必須具備定義『正確性標準』的能力,若驗證者本身缺乏判斷力,AI 僅會加速產生高品質的錯誤代碼。

該內容精準地捕捉了微前端實作中最常見的誤區(將其等同於組件化),並提供了一套具備工程實務價值的遷移路徑。評價為『高度實用』,因其不僅討論技術選型,更觸及組織協作與風險控管(如金絲雀發佈)。但需保留一點:文中對『重複代碼』的寬容度在極端規模的團隊中可能導致維護碎片化,需視具體組織治理能力而定。

該更新將 AI 定位從『知識庫』成功推向『執行體』,其 Programmatic Tool Calling 的引入有效解決了傳統 LLM 在複雜鏈路中的 Token 冗餘痛點,具有極高的實務工程價值。然而,其在資安漏洞挖掘能力的提升雖強大,但依賴分層防禦機制來管控風險,在實際部署的安全性邊界上仍留有變數。

該內容精準地切中了目前 LLM 應用從 Chatbot 轉向 Agent 的核心痛點,即『行為不可預測性』。我評價此觀點具有高度實務價值,因為它將焦點從盲目追求參數規模移至『執行軌跡(Traces)』的數據工程,這是目前工業界最有效的路徑。然而,文中對於合成數據崩潰(Model Collapse)的風險提及較少,在缺乏真實數據錨定時,過度依賴合成數據可能導致模型陷入邏輯迴圈,此為實作時需保留的警覺點。

該內容精準地擊中了當前企業級 AI 落地最核心的痛點:通用性與可靠性的矛盾。其提出的『分層約束』策略具有極高的工程實踐價值,能有效將非決定性的 LLM 輸出轉化為可預測的業務流程。然而,此方案的成敗高度依賴於開發者對『邊界』定義的精準度,若分層邏輯定義模糊,僅會將複雜度從模型端轉移至架構端。