
NVIDIA Nemotron 3 Embed:提升 Agentic Retrieval 效率的嵌入模型新標準
此方案透過優化檢索層(Retrieval Layer)來降低下游推理成本的邏輯極其正確,將 Embedding 模型視為 Agent 的『感官精準度』是高效能架構的關鍵。然而,其效能高度依賴於 NVIDIA 硬體生態(如 Blackwell 與 NIM),對於非 NVIDIA 環境的開發者而言,其量化優勢(NVFP4)將失去意義,建議在考慮部署前先評估基礎設施的兼容性。
此方案透過優化檢索層(Retrieval Layer)來降低下游推理成本的邏輯極其正確,將 Embedding 模型視為 Agent 的『感官精準度』是高效能架構的關鍵。然而,其效能高度依賴於 NVIDIA 硬體生態(如 Blackwell 與 NIM),對於非 NVIDIA 環境的開發者而言,其量化優勢(NVFP4)將失去意義,建議在考慮部署前先評估基礎設施的兼容性。

此案例展現了 AI 從『功能性插件』轉向『結構性營運層』的高階演進,其評價為【極高參考價值】。其成功在於精準地將 LLM 的推理能力與具體的業務邏輯(Business Logic)綁定,而非追求通用對話,但其成效仍依賴於該企業對內部流程的高度數位化程度,對於流程混亂的組織可能難以複製。

該內容精確地捕捉到了 AI Agent 從『對話』轉向『操作』時產生的結構性安全漏洞。我判定此分析具有高度價值,因為它揭示了 LLM 概率預測與嚴格數據解析之間的本質衝突;然而,文中提出的防禦對策(如數據清洗)在實務中會與功能可用性產生嚴重衝突,這意味著目前的 AI Agent 框架在底層邏輯上仍缺乏真正的數據沙箱機制。

該內容精準地捕捉了『自動化速度』與『監控延遲』之間的結構性矛盾,是一篇具備高度實務警示價值的技術分析。其評價為『優良』,因為它不僅揭露了 GenAI 時代特有的資源盜用路徑,還提供了具體且可執行的技術對策,而非僅停留在理論警告;但保留條件在於,文中建議的行為監控(如 CloudTrail)在極大規模呼叫下仍可能產生雜訊,需搭配更精細的異常偵測算法才能完全根除風險。

該內容提供了一個極具價值的工業級 Agent 實作範本,正確地將 LLM 定位為『推理引擎』而非『執行系統』。其核心價值在於提出了用確定性工具(CLI)來對沖模型隨機性的工程路徑,這在對準確度要求極高的垂直領域中是必然趨勢。然而,此方案高度依賴於前期對 CLI 指令集的精準定義,若業務邏輯過於複雜,維護大量 Markdown 技能文件的成本將成為新的瓶頸。

該內容精確地揭露了開發者在實作 LLM 路由時常見的『線性思維』陷阱,其價值在於將討論維度從單一模型能力提升至系統工程層面。我評價此觀點為『高度實務且具前瞻性』,因為它正確地將快取機制與基礎設施開銷納入成本模型;但需保留之處在於,文中未詳細說明該輕量級算法的具體數學實現,使得其『優化邊界』的實作路徑對讀者而言仍具黑盒性質。

此內容精準捕捉了搜尋引擎從『索引』轉向『代理』的範式轉移,其技術分析邏輯清晰,將 LLM 與 Function Calling 的關聯解釋得相當到位。然而,該分析較偏向功能描述,對 API 整合後可能導致的生態封閉化(Walled Garden)風險討論不足,在評價上屬於高品質的技術概論,但缺乏深層的商業競爭批判。
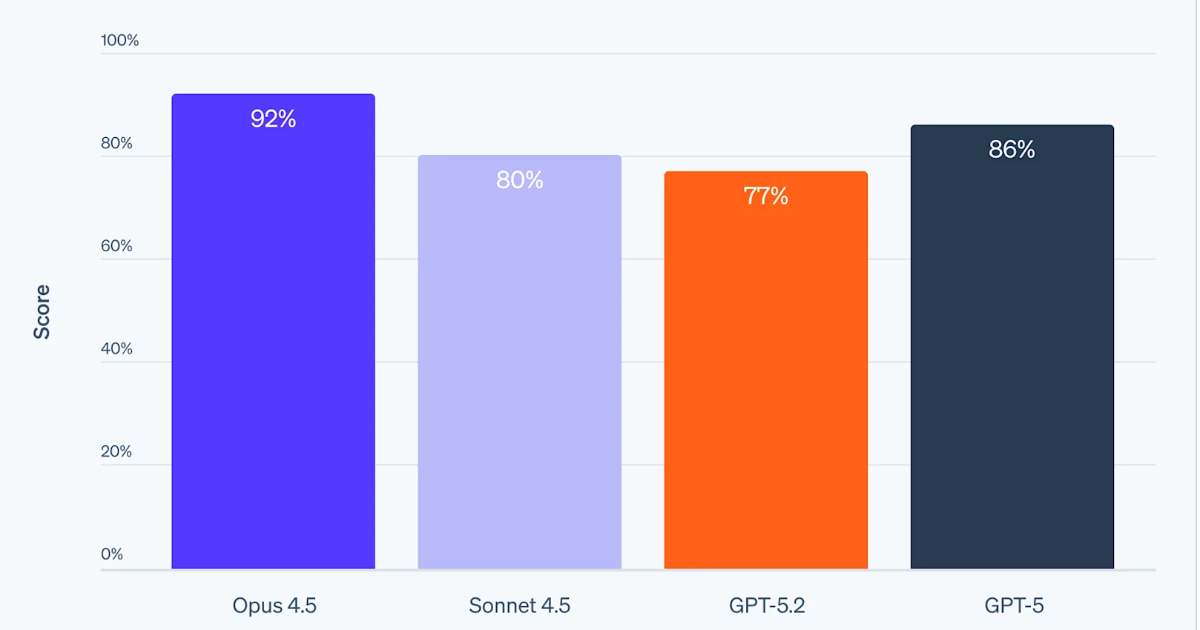
此內容精準捕捉了 AI 開發從『工具』向『代理』轉型的核心痛點。我判定該分析具有高參考價值,因為它將焦點從單純的生成率移至『驗證閉環』,揭示了 AI 在處理負面訊號時的邏輯缺失;然而,其結論仍基於目前模型版本,需保留對下一代模型在自我修正能力(Self-correction)突破後的評估空間。

該內容精準地捕捉到了網路安全架構的代際衝突,正確地將 SASE 的失效歸因於『加密協定演進』與『AI 意圖不可見』這兩大核心矛盾。評價為『高價值技術洞察』,其提出的端點中心論點邏輯自洽,但保留條件在於:實作端點治理將大幅增加設備端資源消耗與管理複雜度,文中對此成本權衡地描述較少。

該內容精準地指出了開發者對『向量資料庫』的盲目崇拜,並提出以關聯式資料庫作為 AI Agent 基石的務實路徑,評價為『高實戰價值』。其邏輯嚴密,正確區分了推播式 RAG 與拉取式 Agentic 模式,但前提是開發者必須具備深厚的 SQL 優化能力,否則多模態整合可能演變為維護噩夢。

該框架展現了 Google 將 AI 開發「工程化」的強烈意圖,將 Agent 視為狀態機而非僅是對話流,這在生產環境中具有極高實用價值。然而,其深度整合 Firebase 生態的傾向可能導致開發者產生平台依賴,在完全去中心化或純私有雲部署的場景下,其優勢可能會被環境限制所抵消。
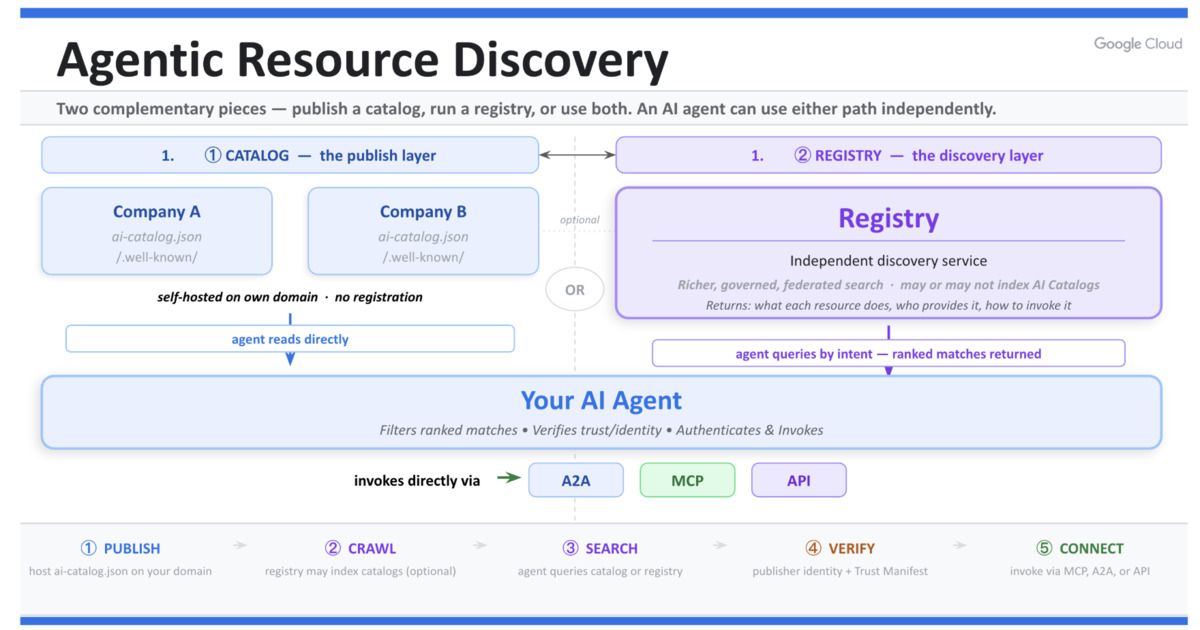
此規範是從『靜態配置』轉向『動態生態』的必要演進,邏輯嚴密且填補了 MCP 在發現階段的空白。然而,其成敗高度依賴於企業對 ai-catalog.json 的維護意願與標準化程度,若缺乏強大的生態驅動力,恐淪為另一套缺乏實作的空殼協議。