
從模型到產品:解析 OpenAI Presence 如何解決企業級 AI Agent 的落地痛點
該內容精準地捕捉了 AI 從『玩具』轉向『工具』的工程轉折點。我判定 OpenAI Presence 是一套成熟的 B2B 治理方案,其價值不在於模型能力的提升,而是在於建立了必要的『約束機制』;然而,該產品目前高度依賴 FDE 人工部署,顯示其通用化程度不足,短期內僅能服務於高預算的大型企業。
該內容精準地捕捉了 AI 從『玩具』轉向『工具』的工程轉折點。我判定 OpenAI Presence 是一套成熟的 B2B 治理方案,其價值不在於模型能力的提升,而是在於建立了必要的『約束機制』;然而,該產品目前高度依賴 FDE 人工部署,顯示其通用化程度不足,短期內僅能服務於高預算的大型企業。

該模型在邊緣端實現『感知-推理-行動』的閉環具有高度工程價值,其將物理常識量化為幾何向量的嘗試極具前瞻性。然而,其性能高度依賴於 NVIDIA 硬體生態的垂直整合,且 4B 參數在極端複雜環境下的泛化能力仍需實測驗證,不能完全替代高精度的物理模擬引擎。

該內容精確捕捉了資深開發者從「實作導向」轉向「決策導向」的心理轉折點,其提出的『對抗孤立感』學習模式具有高度的實務價值。然而,此方案的高度依賴於『同行品質』,若保密小組的成員水平不一,其驗證效果將大打折扣,且高門檻的篩選機制是該模式能否成功的關鍵前提。

該內容精準地捕捉到了當前 AI 工程化從「強控制」轉向「弱耦合」的範式轉移。我評價此方法論為『高效且具前瞻性』,因為它承認了 LLM 推理能力的不可預測性並將其視為特性而非缺陷,透過 Ledger 帳本實現的 Steering Hooks 巧妙地在靈活性與安全性之間取得了平衡。然而,此方案高度依賴底層模型(如 Claude 3.7)的高階推理能力,若部署於中小型模型,其效能將大幅下降,這是一個關鍵的保留條件。

對於許多剛接觸 AI Agent 開發的工程師來說,最容易陷入的誤區是認為只要把 LLM 接上工具(Tools)就能跑。但在企業環境中,真正的挑戰不在於 AI 能不能執行任務,而是在於治理(Governance):誰有權限執行這個動作?如何確保 Agent 不會亂改資料?如何在大...

此內容對 SleeperGem 攻擊路徑的剖析極具價值,精確捕捉了『心理戰術』與『技術規避』的結合。我評價其為高品質的安全預警,因其不僅揭露漏洞,更指出了 RubyGems 被用作死信箱的非典型威脅;但保留條件在於,文中缺乏對特定版本號的具體清單,實務操作上仍需配合即時的 CVE 資料庫。
該方案展現了極高工程成熟度的『降維打擊』,將複雜的管線邏輯坍縮為單一生成任務,在降低延遲的同時提升了全局優化能力。其最核心價值在於量化證明了『數據品質(Context)優於模型規模』,這對工業級 AI 部署具有強大的指導意義。然而,其成功高度依賴於 Netflix 龐大的高品質用戶數據集,在數據稀疏的小規模場景中,此路徑可能無法複製。

這是一起典型的漏洞鏈攻擊案例。攻擊者並非依賴單一漏洞,而是將多個低風險或中風險的漏洞串聯起來,最終達成最高權限的控制。這次受影響的是 SonicWall SMA 1000 系列的 VPN 設備,由安全公司 Volexity 追蹤的威脅組織 UTA0533 在漏洞公開前就已將其作為...

此攻擊案例展現了極高水準的『心理操縱與技術隱匿』結合,評價為:高威脅且極具欺騙性。其核心價值在於將攻擊路徑從『文件傳輸』轉向『使用者主動執行指令』,成功將防禦壓力轉移至人類心理弱點;然而,其依賴使用者對終端機操作的低認知度,若對象為高技術人員,該手法將失效。
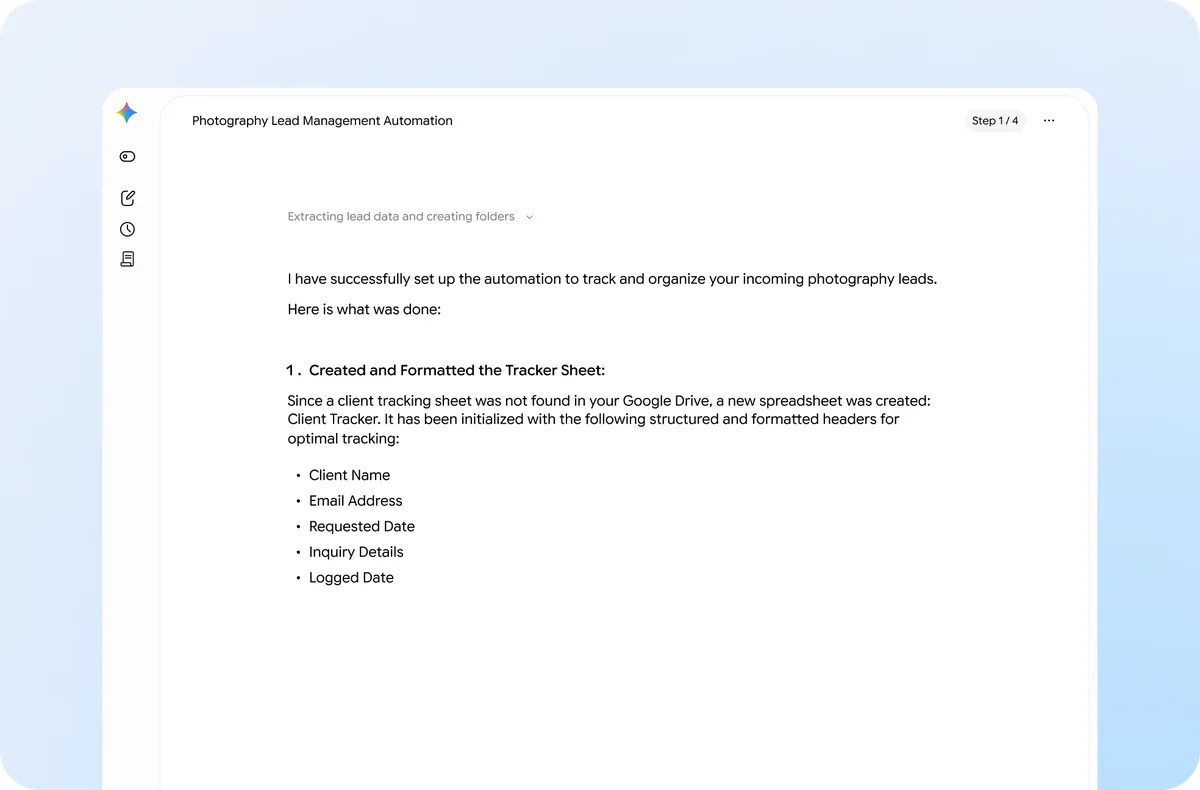
該內容精準地將 AI 從『對話工具』升級為『營運框架』,論點具備高度的實操性,尤其在將非結構化數據轉化為商業邏輯的論述上表現優異。然而,其評價前提是使用者必須具備一定的 Prompt Engineering 能力與 Google 生態系的深度整合,若缺乏對 API 或工作流的基礎認知,文中提到的『自動駕駛模式』將僅停留在理論層面。

此產品將深層研究成功轉化為工程工具,邏輯嚴密且切中企業隱私痛點,評價為『高價值但高門檻』。其優勢在於將優化過程自動化,但其效能完全受限於使用者的評分函數品質,若缺乏嚴謹的邊界測試,該工具可能會演變成高效能的『錯誤產生器』。

AWS 最近為 CloudFormation 推出了 Express Mode(快速模式),旨在解決開發者長期以來對基礎設施部署速度緩慢的抱怨。對於許多習慣使用 Terraform 等工具的工程師來說,CloudFormation 過去最令人詬病的便是部署時的等待時間過長。這次的...