
從 DoorDash 的 Entity Cache 實作看大規模微服務的透明快取架構設計
此方案展現了極高水準的工程實踐,將快取從『業務邏輯』提升至『基礎設施』的高度,徹底解決了開發者重複實作快取導致的維護災難。其對 Cache Stampede 的處理與雙重 TTL 設計極具實戰價值,但在極端強一致性要求的場景下,基於 Kafka 的異步失效機制可能會存在短暫的資料不一致風險。
此方案展現了極高水準的工程實踐,將快取從『業務邏輯』提升至『基礎設施』的高度,徹底解決了開發者重複實作快取導致的維護災難。其對 Cache Stampede 的處理與雙重 TTL 設計極具實戰價值,但在極端強一致性要求的場景下,基於 Kafka 的異步失效機制可能會存在短暫的資料不一致風險。

該方案展現了極高水準的工程實踐,將『邏輯抽象層』引入物理基礎設施以解決分片不均,是應對大規模集群失效的優解。然而,其核心依賴於對 Odin 調度平台的精準控制,若缺乏強大的底層調度能力,強行實施此邏輯分組可能會增加維運複雜度,建議中小型規模集群在採用前需評估管理成本。

該方案在理論上極具前瞻性,成功將身分驗證與儲存層解耦,有效解決了 SaaS 服務商倒閉導致的資料遺失痛點。然而,其在實際部署中仍面臨網路穿透(NAT Traversal)的物理限制與資料解析粒度的權衡問題,因此該架構目前僅適用於對『資料主權』需求極高且對即時同步延遲有一定容忍度的特定場景。

該方案在處理不可變數據集(Immutable Datasets)的同步效率上展現了極高的工程水準,透過繞過 API 直接操作儲存格式(SSTables)精準擊中效能瓶頸,評價為『極其高效且具備前瞻性』。然而,其成功高度依賴於對資料存取模式的精確區分,若將此模式強行套用於高頻變動的可變數據,將導致狀態管理複雜度爆炸,因此該方案僅適用於特定數據場景。

該內容精準地揭露了工程師對 EDA 的『萬靈丹迷思』,透過具體的演進路徑(三代狀態管理)證明了純粹非同步化在亞秒級延遲場景下的無能。其評價為『高價值實務指南』,因其不僅指出問題,還給出了從 Kafka 到 Redis 的具體替代方案;但保留條件在於,文中建議的 Redis 權威存儲會引入單點故障風險,雖提及恢復機制,但未詳細討論 Redis 集群的高可用複雜度。

該內容對現代運維文化有深刻且正確的洞察,成功將技術故障提升至組織治理的高度。其論點足以說服管理層放棄低效的指責文化,但其前提是組織必須具備極高程度的透明度與自我修正能力,否則「無責」可能被誤用為逃避責任的藉口。

該內容精準地捕捉了分散式系統中『效能與容錯』的經典矛盾,具有極高的工程參考價值。我判定此分析為高品質的技術反思,因為它未將故障簡單歸咎於雲端供應商,而是深入挖掘應用層的設計缺陷;但其保留條件在於,文中未詳細說明在維持低延遲前提下,具體的跨 AZ 拓撲優化方案。

該內容精準捕捉了現代軟體開發從『中心化雲端』回歸『邊緣主權』的範式轉移。其論述邏輯嚴密,成功將抽象的數據主權概念具象化為 AT Protocol 與 Automerge 等技術實作,具備高度的工程參考價值。然而,文章對『衝突解決』的技術複雜度描述較為簡略,在實際部署 CRDT 系統時可能面臨比文中描述更嚴峻的狀態爆炸問題,建議讀者在實作前需深入研究記憶體開銷。
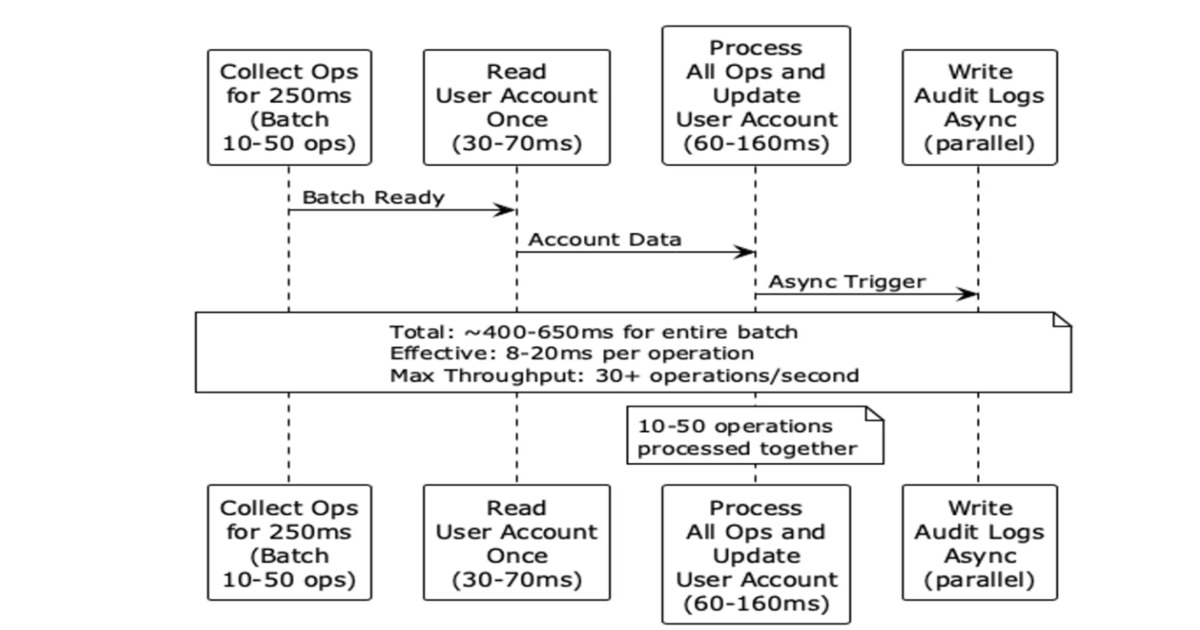
該方案在金融正確性與系統吞吐量之間取得了極高水準的平衡。其核心價值在於將『序列化更新』轉化為『微批次原子更新』,有效解決了熱點帳戶的寫入放大問題。然而,此設計高度依賴於對批次視窗(250ms)的精準調校,若業務流量分佈極端不均或對即時性要求達到毫秒級,該模型可能會在延遲控制上顯露侷限。

該內容精準地捕捉到了分散式系統中一個極易被忽視的效能陷阱——掉隊者問題,其技術分析邏輯嚴密且具備實作層面的可操作性。我評價此方案為『高效但具風險的補救措施』:它能極速壓低 p99 延遲,但其前提是系統必須具備強大的冪等性保障與精準的流量預算控制,否則適應性對沖將在系統臨界點時演變成加速崩潰的導火線。

此案例展示了基礎設施管理從『過程導向』演進至『狀態導向』的必然路徑。我判定該方案在處理狀態化基礎設施(Stateful Infrastructure)上具有極高參考價值,因為它精準地解決了分散式系統中最核心的『一致性』與『恢復力』痛點;然而,其成功高度依賴於對 ScyllaDB 底層特性的深度掌握,若缺乏對 Quorum 等共識機制之理解,單純套用此類框架仍可能在極端邊緣案例中失效。

此內容精準地將複雜的分布式狀態管理概念轉化為可理解的技術分析,評價為『高價值技術指南』。其優點在於明確區分了 V1 與 V2 的底層邏輯差異(確定性執行),而非僅列舉功能更新;但保留條件在於,文中未提供具體的程式碼範例來對比『確定性』與『非確定性』的寫法,對初學者而言仍有實作門檻。